
What “Beyond the Happy Path” Means in Secure Communication
Definition and scope: “Beyond the happy path” means designing secure communication for the messy realities: dropped packets, retries, clock skew, partial failures, duplicated messages, offline clients, key rotation mid-session, server restarts, load balancers, multi-region deployments, and active interference that doesn’t look like a clean cryptographic break. The cryptography can be correct and still fail operationally if you don’t define how endpoints behave when things go wrong.
Goal: Build protocols and application-level patterns that remain secure and usable under failure. This chapter focuses on patterns you can implement on top of standard secure channels (for example, TLS) and within message-based systems (queues, webhooks, mobile sync) without re-teaching basic crypto primitives.
Pattern 1: Treat the Transport as Secure, but Not Sufficient

Why: A secure transport channel protects data in transit, but it does not automatically give you correct application semantics. Problems like replayed requests, duplicated webhook deliveries, and out-of-order events can still cause security-impacting behavior (double charges, privilege changes applied twice, stale state overwriting fresh state).
Practical rule: Use transport security for confidentiality and integrity in transit, then add application-layer protections for message semantics: idempotency, replay resistance, ordering, and explicit binding of requests to user intent.
Step-by-step: Add idempotency to state-changing HTTP APIs
Step 1 — Require an Idempotency-Key: For POST/PUT/PATCH that create side effects, require a client-generated unique key per intended action (not per retry). Return 400 if missing for endpoints that must be safe to retry.
- Listen to the audio with the screen off.
- Earn a certificate upon completion.
- Over 5000 courses for you to explore!

Download the app
Step 2 — Store request fingerprint and result: Persist (user_id, idempotency_key) with a hash of the request body and the response payload/status. If the same key is reused with a different body, return 409 Conflict.
Step 3 — Make the server response deterministic: On retry with the same key and same body, return the stored response exactly. This prevents attackers from forcing inconsistent outcomes via timing or partial failures.
Step 4 — Set retention and scoping: Scope keys to an authenticated principal (user, API token, or client_id) and keep them for a window appropriate to your retry behavior (hours to days). Do not scope globally, or one user could block another by guessing keys.
// Pseudocode for idempotent charge endpoint handler (server-side) handleCharge(req): user = requireAuth(req) key = requireHeader(req, "Idempotency-Key") bodyHash = sha256(canonicalJson(req.body)) record = db.findIdempotency(user.id, key) if record exists: if record.bodyHash != bodyHash: return 409, {error: "Idempotency key reuse with different payload"} return record.status, record.response // First time: execute side effect within a transaction tx.begin() // Create a pending operation row keyed by (user, key) to lock out races db.insertIdempotency(user.id, key, bodyHash, status="PENDING") result = payments.charge(user, req.body.amount, req.body.source) db.updateIdempotency(user.id, key, status=200, response=result) tx.commit() return 200, resultPattern 2: Replay Resistance for Messages and Webhooks
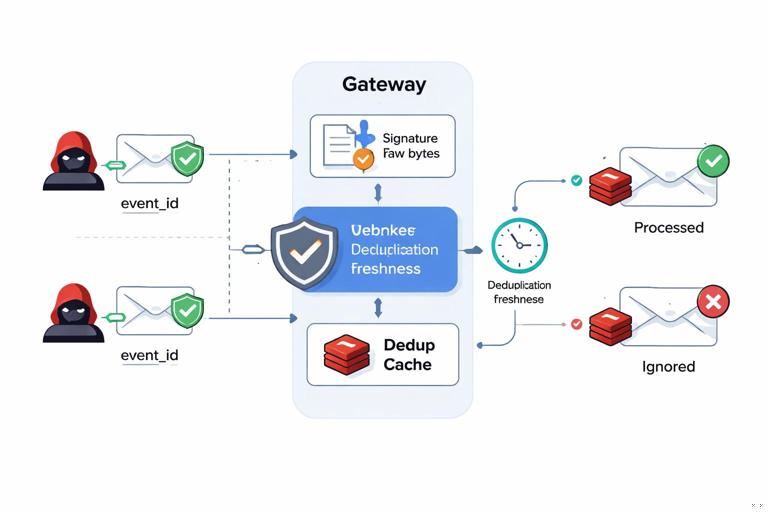
Why: Even with authenticated requests, an attacker or misconfigured proxy can replay previously valid messages. In webhook systems, the sender may also legitimately retry deliveries, so you must distinguish “legitimate retry” from “malicious replay” by using stable identifiers and bounded freshness.
Key idea: Every message that causes a side effect should have a unique message identifier and a freshness signal. The receiver keeps a deduplication cache and rejects messages outside an allowed time window.
Step-by-step: Verify and deduplicate inbound webhooks
Step 1 — Validate authenticity: Verify the webhook signature using the shared secret or public key provided by the sender. Reject if missing or invalid before parsing deeply.
Step 2 — Extract message_id and timestamp: Require fields like event_id and sent_at (or a header). If absent, treat as insecure and reject or route to a quarantine queue.
Step 3 — Enforce a time window: Accept only if sent_at is within, say, 5 minutes (or a window aligned with sender retry policy). Account for clock skew by allowing a small future tolerance.
Step 4 — Deduplicate: Store event_id in a fast store (Redis) with TTL longer than the retry window. If event_id already seen, return 200 OK but do not reapply side effects.
Step 5 — Bind signature to the exact bytes: Verify signature over the raw request body bytes, not a parsed object, to avoid canonicalization differences.
// Pseudocode for webhook receiver handleWebhook(req): raw = req.rawBodyBytes sig = req.headers["X-Signature"] if !verifySignature(raw, sig, WEBHOOK_SECRET): return 401 evt = json.parse(raw) id = evt.event_id ts = parseTime(evt.sent_at) if abs(now() - ts) > 5 minutes: return 400 if redis.setnx("seen:"+id, "1", ttl=24 hours) == false: return 200 processEvent(evt) return 200Pattern 3: Explicit Session Lifecycle and Key Rotation Tolerance
Why: Real systems rotate credentials, restart servers, and migrate traffic. If your session model assumes a single long-lived key or a single server instance, you’ll see failures that developers “fix” by weakening security (disabling checks, extending lifetimes, skipping verification). Instead, define how sessions survive rotation and how clients recover.
Design principle: Prefer short-lived session artifacts with refresh mechanisms, and allow overlapping validity during rotation (“grace periods”) without accepting indefinite old credentials.
Step-by-step: Overlapping key rotation for signed session tokens
Step 1 — Maintain a key set: Keep an active signing key and one or more previous keys for verification only. Distribute the verification set to all services that validate tokens.
Step 2 — Embed key identifier (kid): Include a key id in the token header/metadata so verifiers can pick the right key quickly and avoid trying all keys.
Step 3 — Rotate on a schedule: Generate a new signing key, mark it active, and keep the previous key for a limited overlap window (e.g., 24 hours) to cover in-flight tokens.
Step 4 — Enforce token expiry: Keep access tokens short-lived (minutes). Use refresh tokens or re-authentication for longer sessions. The overlap window should not exceed the maximum token lifetime by much.
Step 5 — Handle “unknown kid” gracefully: If a client presents a token signed with a key you don’t have (due to propagation lag), return a specific error that triggers a refresh or re-login, not a generic 500.
// Verification logic sketch verifyToken(token): header = decodeHeader(token) kid = header.kid key = keyStore.get(kid) if key == null: return error("KEY_NOT_FOUND") if !verifySignature(token, key): return error("BAD_SIGNATURE") claims = decodeClaims(token) if claims.exp < now(): return error("EXPIRED") return claimsPattern 4: Fail Closed, but Provide a Safe Recovery Path
Why: When verification fails, the secure default is to reject. But if rejection strands users or breaks automation, teams are tempted to add insecure bypasses (“accept if timestamp missing”, “skip signature in dev”, “retry forever”). The better approach is to fail closed while offering a recovery path that does not reduce security.
Examples of safe recovery: Trigger token refresh, re-fetch server configuration, re-run device attestation, or require re-authentication. For machine-to-machine integrations, return structured errors that allow the client to rotate credentials or re-sync time.
Step-by-step: Structured error handling for secure clients
Step 1 — Define error categories: Separate transient network errors from authentication failures from authorization failures from replay/clock errors.
Step 2 — Map categories to actions: Network timeout → retry with backoff; EXPIRED token → refresh; KEY_NOT_FOUND → refresh configuration and retry once; BAD_SIGNATURE → stop and alert; CLOCK_SKEW → resync time and retry once.
Step 3 — Ensure retries are bounded: Limit retries and total time. Infinite retries can become a denial-of-service amplifier or cause repeated side effects if idempotency is missing.
Step 4 — Log with correlation IDs: Include a request_id so you can trace failures without logging secrets.
// Client-side decision table (simplified) onError(err): switch err.code: case "NETWORK_TIMEOUT": retryWithBackoff(max=3) case "EXPIRED": refreshToken(); retryOnce() case "KEY_NOT_FOUND": refreshKeySet(); retryOnce() case "CLOCK_SKEW": syncTime(); retryOnce() case "BAD_SIGNATURE": stopAndAlert() default: stop()Pattern 5: Ordering, Causality, and “Stale Writes” Protection
Why: Secure channels don’t guarantee that messages arrive in order or only once. In distributed systems, out-of-order updates can revert security-sensitive state: re-enabling a revoked permission, restoring an old email address, or overwriting a rotated device key.
Core technique: Use versioning and conditional updates so that only the latest state can be applied. This is as much a security control as it is a correctness control.
Step-by-step: Use optimistic concurrency for security-sensitive resources
Step 1 — Add a version field: Store an integer version (or an ETag derived from version) on the resource.
Step 2 — Require If-Match (or version): Clients must send the version they last read when attempting an update.
Step 3 — Reject stale updates: If the version doesn’t match, return 412 Precondition Failed. The client must re-fetch and re-apply changes intentionally.
Step 4 — Apply server-side invariants: Even with correct versions, enforce rules like “revoked permissions cannot be re-added without re-authentication” or “email change requires recent verification.”
// HTTP semantics example GET /user/123 -> ETag: "v7" PUT /user/123 with header If-Match: "v7" if current version != 7: return 412 else: apply update, bump version to 8Pattern 6: Secure Retries Without Amplifying Attacks
Why: Retries are necessary for reliability, but they can amplify attacks: credential stuffing against an upstream, repeated expensive signature checks, or repeated payment attempts. They can also create side effects if not combined with idempotency and deduplication.
Practical guidance: Retries should be bounded, jittered, and aware of error types. Rate-limit by client identity and by operation type. Use circuit breakers to avoid hammering dependencies.
Step-by-step: Implement retry policy with backoff and jitter
Step 1 — Retry only on safe errors: Timeouts, 502/503, connection resets. Do not retry on 4xx auth errors or signature failures.
Step 2 — Use exponential backoff with jitter: For example: base 200ms, multiply by 2 each attempt, add random jitter, cap at 5s.
Step 3 — Cap attempts and total time: For interactive requests, keep total under a few seconds. For background jobs, cap attempts and move to a dead-letter queue.
Step 4 — Combine with idempotency: Ensure the same idempotency key is reused across retries so the server can safely deduplicate.
// Retry timing example attempt 1: 200-400ms attempt 2: 400-800ms attempt 3: 800-1600ms cap: 5s max attempts: 3Pattern 7: Channel Binding and Context Binding
Why: A common “beyond happy path” failure is accepting a valid credential in the wrong context: a token minted for one audience used against another service, a request intended for one tenant replayed against another, or a privileged action executed without proof of recent user intent.
Technique: Bind credentials and requests to context: audience, tenant, device, and the specific action being authorized. This is not about inventing new crypto; it’s about including the right claims and verifying them consistently.
Step-by-step: Bind an API token to audience and tenant
Step 1 — Include audience (aud): The token must specify which service(s) it is valid for. The service rejects tokens with mismatched aud.
Step 2 — Include tenant or account scope: Add tenant_id (or similar) and ensure every request’s path/resource matches that scope.
Step 3 — Include authorized party (azp) for delegated flows: If a token is obtained via a third party, record who obtained it and enforce policy per azp.
Step 4 — Bind high-risk actions to fresh confirmation: For actions like changing payout details, require a recent “step-up” event (recent login, re-auth, or user confirmation) represented as a claim or server-side session state.
// Verification checklist (service-side) verifyClaims(claims, req): require claims.aud == "payments-api" require claims.tenant_id == req.pathTenantId if req.isHighRiskAction: require claims.auth_time > now()-5 minutesPattern 8: Secure Time Handling (Clock Skew, Expiry, and Nonces)
Why: Time is a frequent source of “works in dev, fails in prod.” Mobile devices drift, containers start with wrong time, and multi-region systems see inconsistent clocks. If you rely on timestamps for freshness, you must define skew tolerance and recovery.
Practical approach: Use short validity windows, allow small skew, and prefer server-generated nonces or challenges for the most sensitive operations.
Step-by-step: Challenge-response for high-risk operations
Step 1 — Client requests a challenge: Server returns a random nonce and an expiry time.
Step 2 — Client signs or MACs the operation with the nonce: The nonce is included in the request so the server can ensure freshness without trusting the client clock.
Step 3 — Server verifies and consumes the nonce: Store nonce as “used” (or delete it) so it cannot be replayed. Enforce expiry based on server time.
// Flow sketch 1) POST /payout/change/challenge -> {nonce, exp} 2) POST /payout/change with {nonce, new_payout, proof} 3) Server: verify proof includes nonce; check nonce unused and not expired; mark used; apply changePattern 9: Multi-Device and Offline Clients Without Security Regression

Why: Offline mode and multiple devices introduce conflicts: two devices update the same resource, one device is compromised, or one device lags behind key/session changes. If you “just sync later,” you risk accepting stale or unauthorized updates.
Practical controls: Use per-device identifiers, per-device session tracking, and server-side conflict resolution that is conservative for security-sensitive fields.
Step-by-step: Conservative sync rules for sensitive fields
Step 1 — Tag updates with device_id and last_seen_version: Every mutation includes which device made it and what version it was based on.
Step 2 — Reject or quarantine sensitive stale updates: If a device submits a change to security-sensitive settings (2FA settings, payout info, recovery email) based on an old version, reject with 412 and require re-authentication.
Step 3 — Allow safe merges for non-sensitive fields: For low-risk profile fields, you can auto-merge or last-write-wins, but keep audit logs.
Step 4 — Support device revocation: If a device is revoked, its session tokens should stop working quickly, and its queued offline updates should be rejected.
// Example policy if field in ["payout", "recovery_email", "mfa"] and version mismatch: return 412 + require step-up else: attempt mergePattern 10: Observability That Doesn’t Leak Secrets
Why: When things fail beyond the happy path, engineers need logs and traces. But logging raw requests, headers, or tokens can leak credentials and personal data, turning operational tooling into an attack surface.
Approach: Log metadata, not secrets. Use structured logging with redaction, and include stable correlation identifiers so you can debug without dumping sensitive payloads.
Step-by-step: Safe logging for secure communication failures
Step 1 — Define a redaction policy: Never log Authorization headers, cookies, raw tokens, private keys, or full webhook bodies. Redact or hash identifiers when possible.
Step 2 — Log verification outcomes: Record which check failed (expired, bad signature, replay, stale version) and the request_id/event_id/kid, but not the secret material.
Step 3 — Add metrics: Count failures by reason. Spikes in BAD_SIGNATURE or REPLAY_DETECTED are actionable signals.
Step 4 — Use sampling carefully: Sample only after redaction. Avoid “log on error with full payload.”
// Example structured log {"request_id":"...","event_id":"...","result":"REJECT","reason":"REPLAY_DETECTED","kid":"k2","tenant":"t1"}Putting It Together: A Secure Message Processing Pipeline Under Failure
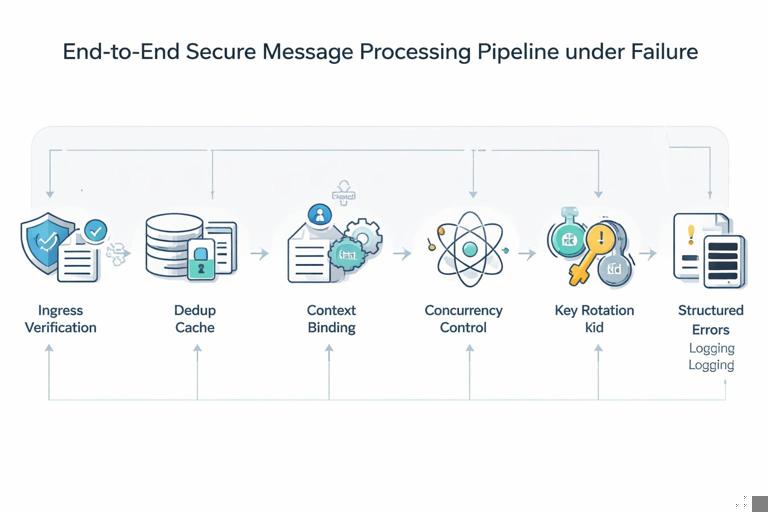
Scenario: You receive signed webhooks that trigger account changes and also expose an API for clients to initiate changes. You want the system to remain safe under retries, duplicates, out-of-order delivery, and key rotation.
- Ingress: Verify signature over raw bytes; enforce timestamp window; deduplicate by event_id; log reason codes without secrets.
- Processing: Apply optimistic concurrency with versions; reject stale writes for sensitive fields; require step-up for high-risk changes.
- Side effects: Use idempotency keys for outbound calls (payments, emails) and store results for deterministic retries.
- Rotation: Verify against a key set with kid; allow overlap; handle unknown kid with a refresh path.
- Recovery: Clients interpret structured errors and take safe actions (refresh, resync time, re-auth) with bounded retries and jitter.
// End-to-end checklist (condensed) 1) Authenticate transport + verify app signature if applicable 2) Check freshness (timestamp or nonce) 3) Deduplicate (event_id / idempotency_key) 4) Validate context binding (audience, tenant, action) 5) Apply concurrency control (If-Match/version) 6) Execute side effects idempotently 7) Emit redacted logs + metrics with reason codes

