
Capstone Goal and Scope
What you are building: a small SaaS that serves a web app and an API, supports team accounts, and stores customer data. The capstone objective is to assemble a coherent, production-ready authentication and data-protection design that you can implement incrementally.
What this chapter focuses on: stitching together secure authentication flows and data protection into a single system design: identity lifecycle, MFA, account recovery, authorization boundaries, secrets handling, encryption at rest strategy, key hierarchy, auditability, and operational runbooks. You will make concrete choices and document them as “security invariants” that your code and infrastructure must preserve.
What this chapter avoids repeating: detailed explanations of threat modeling, entropy, encryption primitives, hashing, password storage, token/cookie mechanics, key management basics, transport security patterns, and general architecture checklists. Assume those are already understood; here we focus on integration and execution.
Reference SaaS Scenario and Security Invariants
Scenario: “AcmeMetrics” is a B2B SaaS. Users belong to organizations (tenants). Each organization has projects. The system stores: user profiles, organization metadata, billing identifiers, and customer-uploaded documents. The web app uses a backend API. There is also a CLI using the same API.
Define invariants (non-negotiables): write these down and treat them like requirements. Example invariants: (1) Every request is authenticated and authorized at the API boundary; UI checks are never sufficient. (2) Tenant isolation is enforced in queries and storage paths. (3) Secrets are never logged. (4) Encryption keys are not stored alongside encrypted data. (5) Recovery flows cannot silently downgrade security. (6) Audit logs are append-only and tamper-evident at least operationally (restricted write access, immutable storage policy).
- Listen to the audio with the screen off.
- Earn a certificate upon completion.
- Over 5000 courses for you to explore!

Download the app
Map data classes: classify data into tiers to drive controls. For example: Tier 0 (keys, secrets), Tier 1 (auth factors, recovery codes), Tier 2 (customer content), Tier 3 (metadata). This classification will determine encryption scope, access policies, and logging redaction.
Identity Model: Tenants, Users, Roles, and Service Accounts
Core entities: model identity explicitly: User, Organization, Membership, Role, API Client (service account), and Session. Avoid embedding “role” on the user globally; roles are per-organization membership.
Role design: keep roles small and composable. Example: Owner, Admin, Member, Billing. Add fine-grained permissions only when needed, and prefer server-side permission checks close to the data access layer.
Service accounts: treat non-human access as first-class. A service account should have: scoped permissions, explicit rotation, and separate audit trails. Do not reuse human sessions for automation.
Tenant isolation enforcement: enforce organization_id scoping at every query. A practical pattern is to require organization_id in every request context and to include it in database access helpers. For example, your repository layer can expose only methods that take org_id and never allow “raw” queries from handlers.
// Pseudocode: repository methods require orgId, preventing accidental cross-tenant access
function getProject(orgId, projectId) {
return db.query("SELECT * FROM projects WHERE org_id=? AND id=?", [orgId, projectId]);
}
Authentication Flows: Web, API, and CLI
Unify around one identity provider boundary: even if you host auth yourself, treat the auth subsystem as a separate boundary with its own endpoints, rate limits, and logs. The API should accept only validated identity context (user_id, org_id, auth_strength, session_id) produced by that boundary.
Web login flow: implement a standard interactive login, then step-up when needed. “Step-up” means requiring a stronger factor for sensitive actions (changing email, enabling API tokens, exporting data, changing billing).
API/CLI flow: prefer short-lived access with refresh or re-auth. For a CLI, you can use a device authorization flow or a browser-based login that returns a code the CLI exchanges. The key capstone point: the CLI should not store long-lived secrets without a rotation story and local protection (OS keychain where possible).
Auth strength in context: carry an auth_strength claim in your server-side session state (e.g., “password-only”, “mfa”, “recent-mfa”). Authorization checks can require a minimum strength for certain endpoints.
// Pseudocode: step-up gate
function requireRecentMFA(ctx) {
if (ctx.authStrength !== "recent-mfa") throw Forbidden("MFA required");
}
MFA and Recovery Without Security Downgrades
MFA enrollment: require re-authentication (step-up) before enrolling or changing MFA. Store MFA state per user: enabled methods, last verified time, and a “MFA required” policy per organization (some orgs mandate MFA).
Recovery codes: generate a set of one-time codes at enrollment. Treat them as Tier 1 data: show once, store only in a form that supports verification, and rotate on use. Operationally, require step-up to view or regenerate them.
Account recovery policy: recovery is where many systems quietly weaken security. Define explicit rules: (1) If MFA is enabled, recovery must be at least as strong as MFA enrollment. (2) Recovery should have a cooling-off period for high-risk changes (email change, MFA removal). (3) Notify the user and organization admins of recovery events.
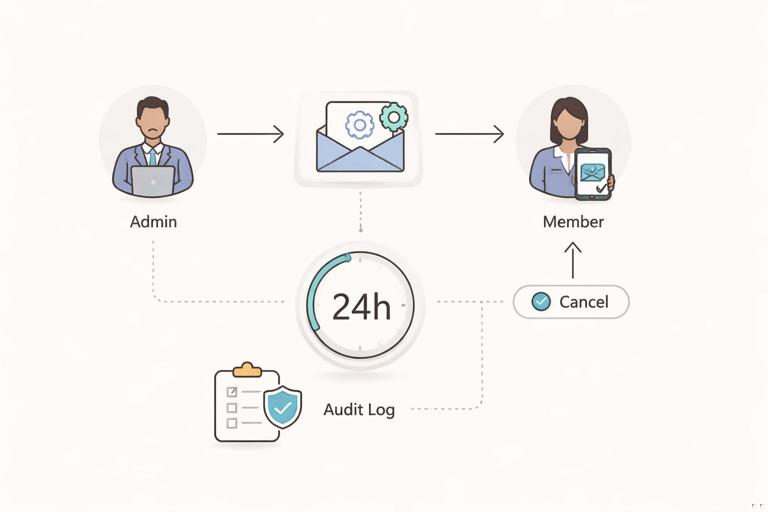
Admin-assisted recovery: for B2B SaaS, consider an organization admin recovery path with strong audit logging and a delay. Example: an admin can initiate “reset MFA” for a member, but the member must confirm via email and the change becomes effective after 24 hours unless canceled.
Authorization: Centralize Decisions, Decentralize Enforcement
Centralize policy: define permissions in one place (a policy module) so you can reason about them. Keep the policy language simple: “subject can perform action on resource in org.”
Enforce close to data: even with centralized policy, enforce checks at the API boundary and again at the data access boundary for critical resources. This reduces the risk of a missed check in a new endpoint.
Object-level access: avoid “role implies access to everything.” For example, a Member may access only projects they are assigned to. Implement assignment tables and enforce them in queries.
// Pseudocode: object-level authorization in query
SELECT p.*
FROM projects p
JOIN project_members pm ON pm.project_id = p.id
WHERE p.org_id = ? AND pm.user_id = ? AND p.id = ?;
Data Protection Strategy: What to Encrypt, Where, and Why
Separate concerns: “encryption at rest” is not one thing. You will likely use multiple layers: (1) storage-level encryption (managed disks), (2) database-level encryption (managed service), and (3) application-level encryption for the most sensitive fields or blobs. The capstone decision is which data needs application-level encryption to reduce blast radius if the database is exposed.
Choose targets for application-level encryption: a practical SaaS baseline: encrypt customer-uploaded documents and a small set of sensitive fields (e.g., third-party API credentials customers store in your system). Do not encrypt everything by default; it complicates querying and indexing. Instead, encrypt what would be most damaging if leaked.
Define access paths: list which services need plaintext. Example: only the “document service” can decrypt documents; only the “integration service” can decrypt third-party credentials. The main API may only request derived outputs. This is a concrete way to reduce internal blast radius.
Key Hierarchy and Envelope Encryption in Practice
Key hierarchy: implement a simple hierarchy: a root key in a managed KMS/HSM, data encryption keys (DEKs) per object or per tenant, and wrapped DEKs stored alongside ciphertext. The KMS key never leaves the KMS; the application requests unwrap operations.
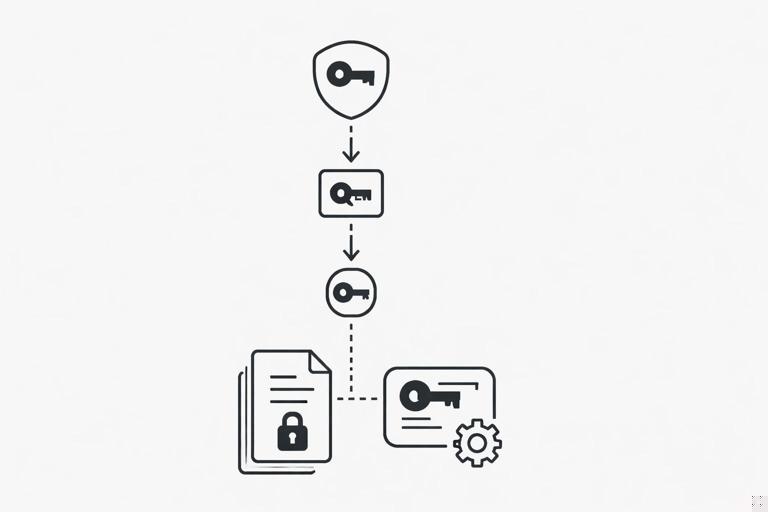
Per-tenant vs per-object DEKs: per-object DEKs give best blast-radius reduction but increase metadata and KMS calls. A common compromise: per-tenant key-encryption key (KEK) in KMS, per-object DEK wrapped by the tenant KEK. This allows tenant-level rotation and object-level isolation.
Rotation plan: define rotation at three layers: (1) KMS root key rotation (managed), (2) tenant KEK rotation (re-wrap DEKs), (3) DEK rotation (re-encrypt data). Most teams start with (1) and (2) and schedule (3) only for high-risk data or after incidents.
// Pseudocode: envelope encryption workflow
// 1) Generate DEK (random)
// 2) Encrypt data with DEK
// 3) Wrap DEK with KMS (tenant KEK)
// Store: ciphertext, wrappedDEK, metadata (alg, version, tenantId)
Protecting Secrets: Configuration, Runtime, and Developer Workflows
Secret inventory: enumerate secrets: database credentials, KMS access, third-party API keys, webhook signing secrets, email provider keys, and internal service-to-service credentials. Assign an owner and rotation interval to each.
Runtime handling: load secrets at runtime from a secret manager; do not bake them into images or repos. Ensure secrets are not exposed via debug endpoints, crash dumps, or metrics labels. Add automated log scrubbing for common patterns (Authorization headers, tokens, private keys).
Developer workflow: provide a safe local dev story: per-developer sandbox secrets, short-lived credentials, and a pre-commit scanner for accidental secret commits. Make the secure path the easiest path.
Audit Logging: Make Security Events Actionable
Define security events: log events that matter: login success/failure, MFA enrollment/removal, recovery initiation/completion, role changes, API token creation, key rotation actions, access to decrypted data, export operations, and admin actions.
Log structure: use structured logs with consistent fields: timestamp, actor_user_id, actor_type (user/service), org_id, action, resource_type, resource_id, auth_strength, ip, user_agent, request_id, result. Avoid logging plaintext sensitive fields; log identifiers and hashes where needed.
Storage and retention: send audit logs to an append-only destination with restricted write access. Define retention based on compliance needs. Provide an internal “audit viewer” with strict access controls and immutable query logging (who viewed the logs).
Step-by-Step Implementation Plan (Incremental, Testable)
Step 1: Write the security invariants as tests and checks
Create a short document and translate key invariants into automated checks. Examples: (a) every handler must call an auth middleware, (b) every DB query must include org_id, (c) sensitive endpoints require recent MFA. Add unit tests for policy decisions and integration tests for tenant isolation.
// Pseudocode: integration test for tenant isolation
// Create orgA project, orgB user; ensure orgB cannot access orgA project
assertForbidden(api.getProject(orgBUserCtx, orgAProjectId));
Step 2: Implement request context and policy module
Define a request context object produced by authentication middleware: user_id, org_id, roles, auth_strength, session_id. Implement a policy module that answers “can(subject, action, resource)”. Ensure every endpoint calls policy checks before data access.
Step 3: Add step-up gates for sensitive actions
Identify sensitive actions and add a “requireRecentMFA” gate. Implement a re-auth flow that upgrades auth_strength for a limited time window. Ensure the window is short and stored server-side.
Step 4: Implement MFA enrollment, verification, and recovery controls
Add endpoints for enrolling MFA, verifying challenges, generating recovery codes, and initiating recovery. Add notifications for security events. Add a cooling-off period for MFA removal and email changes, with cancellation links.
Step 5: Implement application-level encryption for selected data
Pick one data type first (e.g., uploaded documents). Implement envelope encryption with metadata versioning. Store ciphertext and wrapped DEK. Add a decryption service boundary and ensure only that service has unwrap permissions. Add tests that plaintext never appears in logs and that ciphertext is stored.
Step 6: Add key rotation hooks and metadata versioning
Version your encryption metadata from day one: algorithm id, key version, tenant id, created_at. Implement a background job that can re-wrap DEKs when tenant KEKs rotate. Ensure the system can read old versions while writing new versions.
Step 7: Build audit logs and operational dashboards
Emit structured audit events for all security-sensitive actions. Create alerting for anomalies: repeated failed logins, sudden token creation spikes, mass exports, decrypt operations outside expected services, and admin role changes. Ensure on-call runbooks exist for each alert.
Operational Runbooks: What to Do When Things Go Wrong
Incident: suspected credential compromise: actions: revoke sessions, rotate API tokens, force step-up for all users in affected org, require password reset if applicable, and review audit logs for exports and role changes. Provide an org-level “panic button” for owners to revoke all tokens and sessions.
Incident: suspected key exposure: actions: identify which key tier is affected (DEK, tenant KEK, KMS root access). If tenant KEK access is compromised, rotate tenant KEK and re-wrap DEKs; if DEKs are exposed, re-encrypt affected objects. Use audit logs to identify which objects were decrypted and when.
Incident: cross-tenant access bug: actions: disable affected endpoints, deploy a hotfix enforcing org_id scoping, run a query audit to detect anomalous access patterns, notify impacted customers with concrete scope, and add regression tests to prevent recurrence.

Practical Checklist: “Definition of Done” for the Capstone
- All API endpoints require authentication middleware; unauthenticated access is impossible by routing design.
- Authorization policy is centralized; enforcement exists at API and data access boundaries for critical resources.
- Tenant isolation is enforced in every query and storage path; integration tests cover it.
- MFA is supported with step-up for sensitive actions; recovery has explicit anti-downgrade rules and notifications.
- Selected sensitive data uses application-level envelope encryption with versioned metadata and least-privilege decrypt services.
- Secrets are sourced from a secret manager; logs and metrics are scrubbed; developer workflow prevents secret commits.
- Audit logs cover security events, are structured, and are stored in an append-only destination with alerting and runbooks.


