
What “Team Stabilization” Means in a Rescue Context
When a project enters rescue mode after conflict or burnout, the team’s delivery system is usually damaged in two ways at once: (1) the social system (trust, communication, willingness to speak up) and (2) the execution system (focus, flow, decision speed, and quality). Team stabilization is the deliberate, time-boxed work of restoring psychological safety and throughput so the team can deliver predictably again.
This chapter focuses on the people-and-process layer that sits between “we have a recovery plan” and “we can actually execute it.” You may have a sound plan, but if the team is emotionally depleted, afraid of blame, or locked in conflict, the plan will not move. Stabilization is not therapy; it is operational leadership that reduces threat, clarifies expectations, and rebuilds reliable collaboration.
Common patterns after conflict or burnout
- Silence and compliance: People stop raising risks, stop challenging assumptions, and “just do what they’re told.” This looks like alignment but produces late surprises.
- Fragmentation: Subgroups form (e.g., dev vs. QA, product vs. engineering). Information becomes currency, not shared context.
- Hypervigilance: People over-document, over-meeting, and over-escalate to protect themselves, slowing throughput.
- Learned helplessness: The team believes nothing will change, so they stop investing effort in improvement.
- Burnout behaviors: missed handoffs, irritability, reduced creativity, increased defects, and “checkbox” work.
Psychological Safety: The Throughput Multiplier

Psychological safety is the shared belief that the team can speak up, ask for help, admit mistakes, and challenge ideas without fear of humiliation or retaliation. In rescue situations, psychological safety is not a “nice to have.” It directly affects throughput because it determines whether the team surfaces problems early (cheap) or late (expensive).
How low psychological safety destroys delivery
- Risk hiding: People delay bad news until it is undeniable, creating schedule shocks.
- Defect leakage: QA and engineers avoid hard conversations; quality issues ship or rework explodes.
- Decision paralysis: Everyone waits for “cover” from leadership, slowing cycle time.
- Reduced learning: Retrospectives become performative; the same issues repeat.
How to recognize psychological safety issues without “diagnosing” people
Use observable signals, not assumptions about motivation:
- In meetings, the same 1–2 people speak; others stay quiet.
- Questions are framed as accusations (“Who broke this?”) rather than curiosity (“What changed?”).
- People avoid ownership language (“They decided…”, “Someone should…”).
- Escalations happen without attempted peer resolution.
- Work is handed off with minimal context to avoid accountability.
Throughput Recovery: Restoring Flow Without Pushing Harder
Throughput recovery is the process of increasing the amount of valuable work completed per unit time while maintaining quality. After burnout, “push harder” usually backfires: it increases cognitive load, raises defect rates, and deepens resentment. Instead, throughput recovery comes from reducing friction and rework, tightening priorities, and creating a safe environment for fast feedback.
- Listen to the audio with the screen off.
- Earn a certificate upon completion.
- Over 5000 courses for you to explore!

Download the app
Key throughput levers in a destabilized team
- Work-in-progress (WIP) limits: Fewer parallel tasks reduces context switching and increases completion rate.
- Clear “done” criteria: Prevents churn and arguments at handoff points.
- Short feedback loops: Daily integration, quick reviews, early testing.
- Decision latency reduction: Make it easy to get answers quickly (named deciders, office hours).
- Rework prevention: Align on acceptance criteria, reduce ambiguous requirements, and enforce quality gates.
Stabilization Plan: A Practical Step-by-Step Playbook (First 10 Working Days)

The steps below assume you are leading or supporting a rescue effort and need to stabilize the team quickly. Adapt the timing to your context, but keep the sequence: safety first, then flow.
Step 1 (Day 1): Set a “No-Blame, High-Accountability” Operating Mode
Teams in conflict often hear “no blame” as “no accountability.” You need both: no personal attacks, but clear ownership of outcomes.
- Script the reset: In a short meeting, state the operating mode: focus on facts, impacts, and next actions; no character judgments; mistakes are data; commitments matter.
- Define unacceptable behaviors: public shaming, sarcasm, interrupting, side-channeling decisions, and retaliating for raising risks.
- Define expected behaviors: raise risks within 24 hours, ask for help early, document decisions, and close loops.
Practical example: Replace “Why didn’t you test this?” with “What conditions prevented testing, and what change will ensure it happens next time?”
Step 2 (Day 1–2): Run a Stabilization 1:1 Sweep (Not a Performance Review)
Do short, structured 1:1s with each team member (15–30 minutes). The goal is to identify friction, fear, and fatigue that block delivery.
Use consistent questions to avoid the perception of favoritism:
- What is the hardest part of delivering right now?
- Where do you feel blocked most often?
- What conversations are people avoiding?
- What would you change this week to make work sustainable?
- What do you need from me to do your best work?
Capture themes, not quotes. Protect confidentiality unless someone gives explicit permission to share.
Step 3 (Day 2): Establish “Safe Channels” for Raising Issues
In low-safety environments, people won’t raise issues in group settings. Provide multiple channels and make them legitimate.
- Anonymous input: A simple form for “risk/concern/blocker” submissions.
- Office hours: Two short windows per week where the rescue lead is available for quick escalation.
- Buddy escalation: Allow someone to raise an issue on behalf of another person if they fear retaliation.
Commit to response SLAs (e.g., acknowledge within 24 hours, action plan within 72 hours). Safety increases when people see follow-through.
Step 4 (Day 2–3): Create a Team Working Agreement Focused on Conflict Hygiene
A working agreement is a short set of rules for how the team collaborates. Keep it operational and testable.
- Meeting norms: start on time, agenda required, decisions recorded, “disagree and commit” rules.
- Communication norms: no surprise escalations; attempt peer resolution first; use shared channels for decisions.
- Review norms: critique the work, not the person; require actionable feedback; time-box debates.
- After-hours norms: define what is truly urgent; protect recovery time.
Practical example: “If you disagree with an approach, propose an alternative with tradeoffs within 24 hours; otherwise, we proceed with the current plan.”
Step 5 (Day 3–4): Reduce Cognitive Load by Tightening Priorities and WIP
Burned-out teams often have too many simultaneous commitments. Stabilization requires narrowing focus so the team can finish work and regain a sense of progress.
- Set a temporary WIP cap: e.g., each engineer works on at most 1 major item at a time; each QA at most 2 active test threads.
- Define a “stop starting, start finishing” rule: new work enters only when something exits.
- Make interruptions visible: track unplanned work as a separate lane so it doesn’t silently consume capacity.
Practical example: If the team is juggling 18 in-progress items with constant context switching, reduce to 6 in-progress items and enforce completion before pulling new work. Throughput often rises even though “activity” appears lower.
Step 6 (Day 4–5): Repair Handoffs and Interfaces (Where Conflict Often Lives)
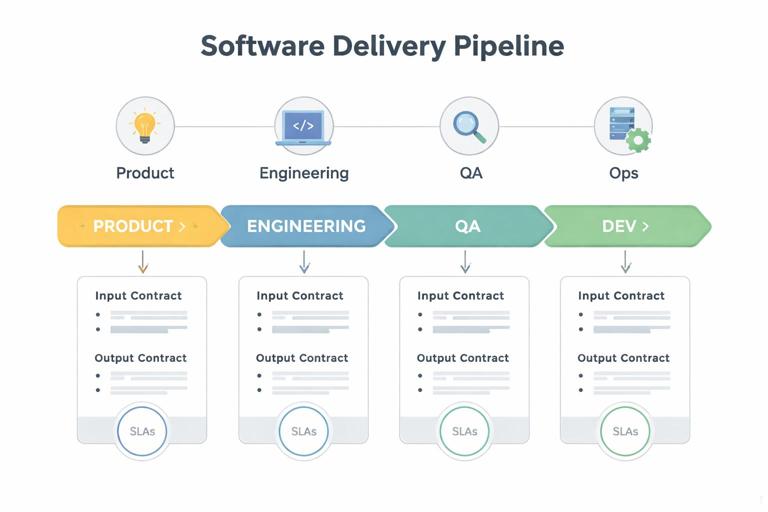
Conflict frequently concentrates at boundaries: product-to-engineering, engineering-to-QA, dev-to-ops, or between component teams. Stabilize these interfaces with explicit contracts.
- Define input quality: what must be true before work starts (acceptance criteria, test data, designs, dependencies).
- Define output quality: what “done” means at handoff (tests run, documentation updated, feature flags, rollback plan).
- Define turnaround times: review SLAs, response times for questions, and escalation paths.
Practical example: If QA feels dumped on at the end, introduce a rule: no story enters “Ready for QA” without passing a defined smoke suite and including test notes. This reduces blame and rework.
Step 7 (Day 5–7): Introduce a Lightweight “Learning Loop” That Doesn’t Re-Traumatize
After conflict, retrospectives can become unsafe. Replace broad “what went wrong” sessions with narrow, process-focused learning loops.
- Use micro-retros: 15 minutes, focused on one workflow (e.g., code review, incident response, estimation).
- Use neutral prompts: “What increased effort?” “What reduced effort?” “What should we try next week?”
- Make changes small and reversible: one experiment at a time; evaluate after a week.
Practical example: Instead of revisiting the entire failed release, run a micro-retro on “Why do PRs wait more than 24 hours?” and implement a rotating reviewer schedule.
Step 8 (Day 6–8): Rebuild Trust Through Visible Fairness and Predictable Decisions
Trust returns when people see consistent rules applied consistently. In rescue mode, perceived unfairness (who gets blamed, who gets protected, who gets the “good work”) can reignite conflict.
- Make decision criteria explicit: why priorities are chosen, why tradeoffs are made.
- Rotate load: distribute on-call, urgent fixes, and “glue work” fairly.
- Protect focus time: don’t punish the team with constant meetings; use short, disciplined syncs.
Practical example: If one senior engineer is always pulled into emergencies, throughput and morale drop. Create an “interrupt captain” rotation so the burden is shared and predictable.
Step 9 (Day 7–9): Address Burnout with Capacity Rules, Not Motivational Speeches
Burnout recovery requires structural changes. People need to see that the system will not keep consuming them.
- Set sustainable hours as a policy: define what “normal” looks like and what requires explicit approval.
- Introduce recovery buffers: schedule slack for stabilization work (automation, refactoring, documentation) that reduces future load.
- Stop heroics as a strategy: celebrate prevention and smooth delivery, not last-minute rescues.
Practical example: If weekend work has become routine, declare a two-week “no weekend work” rule except for true production incidents, and track exceptions publicly with reasons. This forces prioritization discipline and signals respect.
Step 10 (Day 8–10): Measure Safety and Throughput with Simple, Non-Punitive Metrics
Measurement should help the team learn, not create fear. Use a small set of indicators and review them in a calm cadence.
- Psychological safety pulse: weekly 3-question anonymous check (e.g., “I can raise concerns,” “I can ask for help,” “Conflicts are handled respectfully”) on a 1–5 scale.
- Flow metrics: cycle time, WIP, blocked time, and rework rate (e.g., reopened tickets, defect escape).
- Reliability signals: percentage of work completed as planned in the week, not to punish but to detect overload.
When metrics worsen, treat it as a system signal: “What changed?” not “Who failed?”
Conflict De-Escalation Techniques You Can Use Immediately
Use “Ladder of Inference” language to separate facts from stories
In conflict, people jump from observation to accusation. Slow the jump by explicitly separating what happened from what it means.
- Facts: “The deployment was delayed by 6 hours.”
- Interpretation: “It seems like QA is blocking releases.”
- Impact: “We missed the stakeholder demo.”
- Request: “Can we agree on a pre-deploy checklist and a cutoff time for new changes?”
Use “Two-Track” conversations: relationship repair + task resolution
Some disputes are not about the task; they are about respect, fairness, or past injuries. Address both tracks explicitly.
- Relationship track: “The last few handoffs felt adversarial. I want us to reset how we work together.”
- Task track: “For this release, we need a shared definition of ready and a testing window.”
Use time-boxed mediation with a written output
When two parties are stuck, run a 30–45 minute mediation with strict structure:
- Each side gets 5 minutes uninterrupted to describe impact.
- Facilitator summarizes neutrally.
- Identify 1–2 agreements and 1 open question.
- Write the agreements as operational rules (not intentions).
This prevents circular arguments and creates a reference point.
Leader Behaviors That Create Safety Fast (and Those That Destroy It)

High-impact safety behaviors
- Model fallibility: “I missed that risk; here’s what I’ll change.” This gives permission for honesty.
- Reward early bad news: thank people for raising issues quickly; act on them.
- Ask genuine questions: “What am I not seeing?” and wait long enough for answers.
- Close loops: if someone raises a concern, respond with what will happen next and by when.
Safety killers to eliminate
- Public blame: even subtle sarcasm teaches silence.
- Inconsistent standards: exceptions for favorites or senior staff.
- Ambiguous ownership: unclear decision rights create political fights.
- Performative listening: collecting feedback without action increases cynicism.
Practical Templates
Template: Team Working Agreement (One Page)
Purpose: Deliver predictably while treating each other with respect. Duration: 4 weeks (then revise). Owner: Team lead. Review cadence: weekly (10 min). Meeting norms: - Agenda required for meetings > 15 min - Decisions recorded in shared channel within 2 hours - One conversation at a time; no interruptions Communication norms: - Raise blockers within 24 hours - No surprise escalations; attempt peer resolution first - Use shared channels for decisions; avoid private decision-making Review norms: - Critique work, not people - Feedback must be actionable - PRs reviewed within 24 business hours (or explicitly deferred) Sustainability norms: - Normal hours: __ to __ - After-hours work requires explicit approval except incidents - Rotate interrupt duty weeklyTemplate: Weekly Psychological Safety Pulse (Anonymous)
Rate 1 (strongly disagree) to 5 (strongly agree): 1) I can raise risks or concerns without negative consequences. 2) When I make a mistake, it is treated as a chance to improve the system. 3) Conflicts are handled respectfully and lead to clear decisions. Optional free text: What is one thing we should change next week to make delivery easier?Template: Blocker Triage Script (Daily, 10 Minutes)
1) What is blocked right now? (List items, not stories) 2) What is the next smallest action to unblock each item? 3) Who owns that action and by when? 4) What decision is needed, and who is the decider? 5) What can we stop or delay to protect focus?Worked Example: Stabilizing a Team After a Blame-Filled Release Failure

Scenario: A release failed, causing a customer-visible incident. Engineering blames QA for “being slow,” QA blames engineering for “throwing unstable builds,” and product blames both for missing commitments. People are exhausted; two engineers are considering leaving.
Stabilization actions:
- Day 1: The rescue lead sets a no-blame/high-accountability rule and bans public blame language. A short meeting establishes that the goal is to restore reliable releases, not assign fault.
- Day 2: 1:1 sweep reveals QA is overwhelmed by late changes and unclear acceptance criteria; engineers feel constant pressure and fear escalation.
- Day 3: A working agreement is created: no changes after a daily cutoff time without explicit approval; PR review SLA; definition of ready for QA; shared incident notes.
- Day 4: WIP is capped; the team stops starting new features and focuses on finishing the top 5 items needed for a stable release.
- Day 5: Interface contract is implemented: builds must pass smoke tests before QA; QA provides a standard test report format; engineering provides release notes.
- Week 2: Micro-retros focus on PR wait time and flaky tests. The team introduces a reviewer rotation and quarantines flaky tests with a plan to fix them.
Resulting operational changes: fewer late surprises, faster handoffs, reduced conflict at boundaries, and a visible sense of progress that supports burnout recovery.


