
What “Quality and Requirements Recovery” Means in a Rescue Context
When a project is in trouble, teams often try to “go faster” by cutting analysis, skipping acceptance criteria, or deferring testing. That usually creates the opposite result: more rework, more defects, more stakeholder frustration, and a widening gap between what was built and what was needed. Quality and requirements recovery is the deliberate effort to clarify outcomes, make quality measurable, and create a shared definition of “done” so delivery becomes predictable again.
In a rescue context, requirements recovery is not about writing a perfect specification. It is about restoring a reliable chain from business outcomes to user needs to acceptance criteria to tests. Quality recovery is not about adding more QA at the end. It is about preventing defects and misunderstandings earlier by tightening feedback loops and making quality visible in day-to-day work.
The goal is to stop the rework cycle by answering three questions with evidence and shared agreement: (1) What must be true for this project to be considered successful? (2) How will we know, objectively, that each increment meets that bar? (3) What is the minimum set of requirements and quality controls needed to deliver safely and sustainably?
Common Failure Patterns That Drive Rework
Outcome ambiguity disguised as “flexibility”
Stakeholders may say “we’ll know it when we see it,” or teams may accept vague goals like “modernize the experience.” Flexibility is valuable, but ambiguity without decision rules creates churn. The team builds something, feedback arrives late, and the work is re-litigated.
Requirements exist, but are not testable
Statements like “must be user-friendly,” “fast,” or “secure” are important but incomplete. Without measurable thresholds and acceptance criteria, teams cannot verify completion, and stakeholders cannot confidently accept.
- Listen to the audio with the screen off.
- Earn a certificate upon completion.
- Over 5000 courses for you to explore!

Download the app
Quality is treated as a phase, not a property
If testing is concentrated at the end, defects accumulate and become expensive to fix. In rescue situations, late defects also destroy credibility because they appear as “surprises” even when they were predictable.
Multiple sources of truth
Requirements scattered across emails, slide decks, tickets, and meeting notes lead to inconsistent interpretations. Two teams can implement conflicting behaviors while both believe they are correct.
Hidden non-functional requirements (NFRs)
Performance, reliability, privacy, accessibility, auditability, and operational support needs are often implied but not specified. These surface late (e.g., during security review or production readiness), causing major rework.
Core Artifacts to Rebuild: A Minimal, High-Leverage Set
1) Outcome statements with measurable success criteria
Define 3–7 outcomes that matter to the business and users, each with a measurable indicator. Example: “Reduce average onboarding time from 12 minutes to 5 minutes for new customers” or “Increase first-contact resolution from 62% to 75%.” These are not feature lists; they are results.
2) A single requirements backbone
Create one authoritative place where the current requirements live. This can be a structured document, a requirements tool, or a well-governed backlog. The key is governance: every requirement has an owner, a status, and traceability to outcomes.
3) Acceptance criteria and examples
For each deliverable, define acceptance criteria that are observable and testable. Use examples (input/output scenarios) to remove interpretation. Example-based criteria are especially powerful in rescue situations because they reduce debate.
4) A “Definition of Done” that includes quality gates
Definition of Done (DoD) is the team’s contract for what “complete” means. In recovery, DoD must include quality activities that prevent rework: code review, automated tests, security checks, documentation updates, and acceptance verification.
5) A non-functional requirements checklist with thresholds
Capture NFRs as explicit constraints with measurable thresholds (e.g., “p95 response time < 300ms for search,” “RPO 15 minutes,” “WCAG 2.1 AA,” “audit log retention 7 years”). Tie them to acceptance and release readiness.
Step-by-Step: Requirements Recovery Workshop (Fast, Structured, Practical)
This is a lightweight sequence you can run in 2–4 sessions to stabilize requirements without stalling delivery.
Step 1: Establish the “decision frame” for requirements
- Timebox: 30–60 minutes.
- Participants: product owner/sponsor, delivery lead, QA lead, architect/tech lead, key business representative(s).
- Output: a written rule for how decisions will be made and who approves what.
Define: Who is the final decision-maker for scope and acceptance? What is the escalation path? What is the turnaround time for requirement questions (e.g., 24–48 hours)? In rescue mode, slow decisions are a major source of rework because teams proceed with assumptions.
Step 2: Reconfirm outcomes and translate them into “must-have capabilities”
- Timebox: 60–90 minutes.
- Output: a short list of capabilities, each mapped to an outcome.
Ask: “If we deliver only what is necessary to achieve the outcomes, what capabilities must exist?” Keep this at capability level, not detailed UI. Example for a customer support portal: “Search knowledge base,” “Create case,” “Track case status,” “Upload attachments,” “Role-based access.”
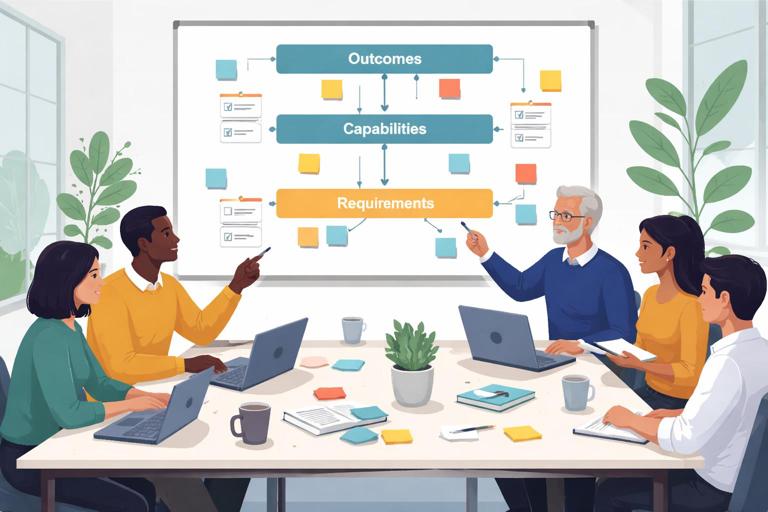
Step 3: Build a requirements map with three layers
Create a simple structure that prevents drift:
- Layer A: Outcomes (measurable results).
- Layer B: Capabilities (what the solution must enable).
- Layer C: Requirements (detailed behaviors and rules).
Every requirement must link upward to a capability and outcome. If it cannot, it is a candidate for deferral or removal. This mapping is a powerful rework-prevention tool because it reduces “pet features” and clarifies why something exists.
Step 4: Convert ambiguous requirements into testable acceptance criteria
Use a consistent template. For each requirement, add:
- Acceptance criteria (observable conditions).
- Examples (scenarios, edge cases).
- Data rules (validation, defaults, error handling).
- Dependencies (systems, roles, data sources).
Example conversion:
Ambiguous: “The system should load quickly.”
Recovered: “For authenticated users, the dashboard page loads with p95 < 2.0 seconds under 500 concurrent users in the staging performance test; critical widgets render within 1.0 second; if a widget fails, the page still loads and shows an error state.”
Step 5: Identify and lock “quality-critical” requirements
Not all requirements carry equal risk. In rescue mode, explicitly mark requirements that, if wrong, cause major rework or compliance risk. Examples: pricing calculations, permissions, data retention, audit logs, integrations, and regulatory workflows. These should receive earlier validation (prototype, spike, or test-first approach) and more rigorous acceptance.
Step 6: Validate with stakeholders using structured walkthroughs
Replace open-ended review meetings with walkthroughs that force clarity:
- Walk through 5–10 key user journeys end-to-end.
- For each step, confirm rules, data, and error handling.
- Capture decisions immediately in the single source of truth.
Use “decision logs” for contested items: what was decided, who decided, and what evidence was used. This prevents rework caused by later “I thought we agreed…” disputes.
Step-by-Step: Quality Recovery Without Slowing Delivery
Step 1: Define “quality” in operational terms
Quality must be measurable and tied to risk. Create a short quality profile for the project:
- Correctness: key calculations, workflows, and permissions behave as specified.
- Reliability: error handling, retries, graceful degradation.
- Performance: response times, throughput, batch windows.
- Security & privacy: authentication, authorization, encryption, logging, data minimization.
- Usability & accessibility: task completion, WCAG criteria if applicable.
- Operability: monitoring, alerting, runbooks, support workflows.
For each dimension, define thresholds and how they will be tested. If you cannot test it, you cannot reliably claim it.
Step 2: Establish a recovery Definition of Done (DoD)
In troubled projects, “done” often means “merged” or “deployed to a test environment.” Replace that with a DoD that prevents rework. Example DoD items:
- Acceptance criteria met and demonstrated with agreed scenarios.
- Automated unit tests added/updated for core logic.
- Critical paths covered by automated integration tests (where feasible).
- Security checks completed for changes affecting auth, data, or external exposure.
- Performance impact assessed for changes touching hot paths.
- Observability updated: logs/metrics/traces for new behaviors.
- Documentation updated: user-facing notes and operational runbook entries.
Keep DoD short enough to be used daily, but strict enough to change behavior.
Step 3: Introduce “quality gates” at the right points
Quality gates are decision points where work cannot proceed without meeting criteria. In recovery, gates should be minimal but non-negotiable for high-risk items:
- Before build: requirement has acceptance criteria and examples.
- Before merge: tests pass, code review complete, static checks clean.
- Before release: end-to-end scenarios pass, NFR checks met, rollback plan ready.
Gates reduce rework by catching issues when they are cheapest to fix.
Step 4: Create a defect policy that supports learning, not blame
Define how defects are logged, prioritized, and prevented from recurring:
- Severity definitions (e.g., Sev1 blocks release, Sev2 workaround exists, Sev3 cosmetic).
- Entry criteria for a defect (steps to reproduce, expected vs actual, environment, logs).
- Root cause tagging (requirements gap, test gap, code defect, environment issue).
- Recurrence rule: if a defect repeats, add a test or acceptance example.
This turns defects into requirements and test improvements, shrinking rework over time.
Practical Example: Recovering Requirements for a Billing Feature

Scenario: A subscription billing project is failing UAT repeatedly. Stakeholders report “incorrect invoices,” but the team cannot reproduce consistently. The backlog contains stories like “Generate invoice” and “Apply discounts,” with minimal acceptance criteria.
Recovery actions
- Clarify outcomes: “Invoices must match contract terms; disputes reduced by 50%; month-end close completes within 6 hours.”
- Identify quality-critical requirements: proration rules, tax calculation, discount precedence, rounding policy, currency handling, invoice numbering, audit logs.
- Convert to testable rules: define a calculation specification with examples: “If customer upgrades mid-cycle, prorate remaining days using daily rate; round to 2 decimals using bankers rounding; taxes applied after discounts.”
- Build acceptance examples: create a table of scenarios with inputs and expected invoice lines.
- Align DoD: “No billing story is done until it passes the scenario table in automated tests.”
Example acceptance criteria snippet
Scenario: Upgrade mid-cycle with discount and tax
Given a customer on Plan A ($100/month) starting Jan 1
And upgrades to Plan B ($150/month) on Jan 16
And has a 10% promotional discount
And tax rate is 8.25%
When the invoice is generated for Jan
Then the invoice includes:
- Credit for unused portion of Plan A (Jan 16–Jan 31)
- Charge for remaining portion of Plan B (Jan 16–Jan 31)
- Discount applied to charges before tax
- Tax applied after discount
- Total rounded to 2 decimals using bankers roundingThis kind of example-based requirement dramatically reduces rework because it removes interpretation and creates a shared test oracle.
Preventing Rework Through Better Requirement Hygiene
Use “requirement readiness” criteria before work starts
Define a simple checklist for when a story is ready for development:
- Clear user/value statement and linked outcome/capability.
- Acceptance criteria written and reviewed.
- At least one example scenario, including an error/edge case.
- Data fields and validation rules identified.
- NFR impact considered (performance/security/accessibility).
- Dependencies identified (APIs, data sources, roles).
If a story fails readiness, it is not “blocked by the team”; it is incomplete input. This reframes the conversation and reduces churn.
Control change with lightweight versioning and decision logs
Rework often comes from silent requirement changes. Use:
- Decision log: date, decision, owner, rationale, affected items.
- Requirement versioning: even simple “v1/v2” markers with change notes.
- Impact note: when a change is made, record what must be re-tested.
This makes change explicit and reduces accidental regressions.
Make non-functional requirements first-class backlog items
If NFRs are only mentioned in architecture documents, they will be forgotten. Represent them as backlog items with acceptance criteria and tests. Example: “Add rate limiting to public API: 100 requests/min per token; return 429 with retry-after header; log throttling events.”
Techniques for Clarifying Outcomes When Stakeholders Disagree
Use “tradeoff questions” to force prioritization
When stakeholders want everything, ask questions that require choosing:
- “If we can only optimize one: speed of delivery or feature completeness, which wins for the next release?”
- “Which user group must be delighted first, and which can be merely supported?”
- “Which failure is unacceptable: wrong data, slow performance, or limited functionality?”
Document the answers as constraints and acceptance thresholds.
Define “minimum lovable” vs “minimum viable” carefully
In rescue mode, teams sometimes overcorrect and ship something technically complete but unusable. Clarify what “usable” means with measurable criteria: task completion time, error rate, support burden, or training time. Convert these into acceptance tests or pilot success metrics.
Integrating Quality and Requirements Recovery Into Daily Execution
Daily requirement clarification loop
Set a short daily slot (15–30 minutes) where developers and QA can ask requirement questions and get decisions quickly. The purpose is to prevent “assumption-driven development,” a major rework driver.
Three-amigo reviews for high-risk items
For quality-critical stories, run a brief review with product, dev, and QA to confirm acceptance criteria and examples before implementation. This is a small investment that prevents large downstream rework.
Demo against acceptance criteria, not against “what we built”
In rescue situations, demos can become subjective. Anchor demos to the acceptance criteria and example scenarios. If a criterion is not met, it is not a debate; it is incomplete work or a requirement change that must be logged.
Quick Reference Templates You Can Copy
Outcome statement template
Outcome: [Business/user result]
Metric: [How measured]
Baseline: [Current value]
Target: [Desired value]
Timeframe: [By when]
Owner: [Decision-maker]
Notes: [Constraints/assumptions]Requirement template (testable)
ID: [REQ-###]
Linked outcome/capability: [Outcome X / Capability Y]
Statement: [What the system must do]
Acceptance criteria:
- [Observable condition 1]
- [Observable condition 2]
Examples:
- Scenario A: [inputs] -> [expected outputs]
- Scenario B (edge/error): [inputs] -> [expected behavior]
NFR considerations: [performance/security/accessibility/operability]
Dependencies: [systems/roles/data]
Owner: [Approver]Recovery Definition of Done (starter)
Done means:
- Acceptance criteria met and demonstrated
- Tests added/updated for critical logic
- Code reviewed and merged with checks passing
- Security/privacy considerations addressed (if applicable)
- Observability updated (logs/metrics for new behavior)
- Release notes/runbook updated (if applicable)

