
Por que a modelagem é o “alicerce” do seu dashboard
Modelagem, no Power BI, é a forma como você organiza as tabelas e os relacionamentos para que os cálculos funcionem de maneira previsível. Em pequenos negócios, o objetivo é ter um modelo simples, fácil de manter e confiável para responder perguntas do dia a dia: quanto vendi, em quais produtos, em quais canais, por qual vendedor, em que período, com qual margem (quando houver custos), e como isso se conecta com estoque e caixa.
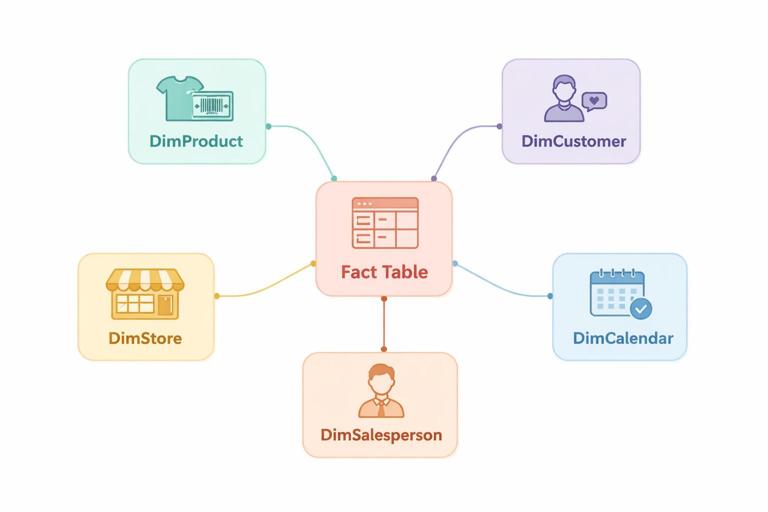
Um modelo bem feito reduz retrabalho, evita medidas “gambiarras” e diminui erros comuns como totais incorretos, duplicidades e filtros que não se comportam como esperado. A base dessa simplicidade é o padrão de tabela fato + tabelas dimensão, com uma definição clara de granularidade (o nível de detalhe de cada tabela).

Conceitos essenciais: fato, dimensão e granularidade
Tabela fato: onde estão os eventos mensuráveis
Tabela fato é a tabela que registra acontecimentos do negócio em um nível de detalhe definido. Ela costuma ter:
- Chaves que apontam para dimensões (ex.: ProdutoID, ClienteID, DataID, LojaID).
- Métricas numéricas agregáveis (ex.: Quantidade, Valor, Desconto, Custo, Imposto, Frete).
- Muitas linhas (cresce rápido com o tempo).
Exemplos típicos de fatos em pequenos negócios:
- FatoVendas: cada linha representa um item vendido (ou uma nota/pedido, dependendo da granularidade).
- FatoMovEstoque: entradas e saídas de estoque (compra, venda, ajuste, devolução).
- FatoRecebimentos: pagamentos recebidos (por venda, por parcela, por data de liquidação).
- FatoDespesas/Pagamentos: pagamentos efetuados (por data de competência ou pagamento).
Tabela dimensão: o “cadastro” que dá contexto
Dimensões descrevem “quem”, “o quê”, “onde” e “como” os eventos aconteceram. Elas têm:
- Ouça o áudio com a tela desligada
- Ganhe Certificado após a conclusão
- + de 5000 cursos para você explorar!

Baixar o aplicativo
- Menos linhas (cadastros).
- Colunas descritivas para segmentar e filtrar (ex.: Categoria, Marca, Canal, Cidade, Status).
- Uma chave única por registro (ex.: ProdutoID único por produto).
Exemplos de dimensões:
- DimProduto (ProdutoID, Nome, Categoria, Marca, Unidade, Ativo/Inativo).
- DimCliente (ClienteID, Nome, Segmento, Cidade, UF).
- DimVendedor (VendedorID, Nome, Equipe).
- DimLoja (LojaID, Nome, Região).
- DimCanal (CanalID, Canal: balcão, delivery, marketplace).
- DimCalendario (Data, Ano, Mês, Trimestre, Semana, Dia da semana, etc.).
Granularidade: o nível de detalhe que define o que é possível calcular
Granularidade é a pergunta: “o que cada linha representa?”. Definir isso evita confusão e cálculos errados.
Exemplos de granularidade em vendas:
- Item da venda: cada linha é um produto dentro de um pedido/nota. Permite analisar mix de produtos, ticket por item, margem por produto, etc.
- Cabeçalho da venda: cada linha é um pedido/nota. Mais simples, mas perde detalhes por produto.
- Diário por produto: cada linha é Produto + Data com valores já somados. Bom para performance, mas limita análises (ex.: não dá para ver por cliente se o cliente não estiver na granularidade).
Regra prática: escolha a granularidade mais detalhada que você realmente precisa para responder as perguntas do negócio, sem exagerar. Para a maioria dos dashboards de vendas e estoque, venda por item e movimento de estoque por evento são escolhas robustas.
Modelo estrela (Star Schema): o desenho mais simples e confiável
O modelo estrela organiza o dataset com:
- Uma ou mais tabelas fato no centro.
- Várias dimensões ao redor, ligadas por relacionamentos 1:* (um para muitos).
Por que isso é confiável?
- Filtros fluem das dimensões para os fatos de forma previsível.
- Medidas ficam mais simples (SUM, COUNT, DISTINCTCOUNT com contexto correto).
- Evita ambiguidade de relacionamentos e “caminhos” duplicados.
Em pequenos negócios, a tentação é juntar tudo em uma tabela única (“tabelão”). Isso pode até funcionar no começo, mas tende a gerar:
- Colunas repetidas (ex.: nome do produto repetido em milhares de linhas).
- Maior tamanho do modelo.
- Mais chance de inconsistência (produto escrito de formas diferentes).
- Dificuldade para manter cadastros (mudou a categoria? precisa atualizar histórico inteiro).
Passo a passo prático: desenhando o modelo antes de criar medidas
Passo 1 — Liste as perguntas que o modelo precisa responder (sem falar de KPIs)
Sem repetir capítulos anteriores, foque no tipo de corte/segmentação que você precisa:
- Analisar vendas por período (dia/mês/ano).
- Comparar por produto/categoria/marca.
- Comparar por canal, loja e vendedor.
- Relacionar vendas com movimentações de estoque.
- Relacionar vendas com recebimentos (quando houver parcelamento).
Isso define quais dimensões são necessárias e quais fatos precisam existir.
Passo 2 — Defina a granularidade de cada fato
Escreva literalmente a frase “Cada linha representa…”. Exemplos:
- FatoVendas: cada linha representa um item de uma venda (PedidoID + ItemID ou NotaID + Sequência).
- FatoRecebimentos: cada linha representa um recebimento (parcela paga) com data de liquidação.
- FatoMovEstoque: cada linha representa um movimento (entrada/saída/ajuste) para um produto em uma data/hora.
Esse passo evita erros como tentar calcular “quantidade vendida” a partir de uma tabela de recebimentos (granularidade diferente) ou tentar conciliar estoque com uma tabela de vendas que não tem ProdutoID consistente.
Passo 3 — Garanta chaves estáveis (IDs) para dimensões
Relacionamentos confiáveis dependem de chaves. Em vez de relacionar por nome (ex.: “Produto”), use um identificador (ex.: ProdutoID). Se sua fonte não tem IDs, você pode criar uma chave no Power Query (por exemplo, combinando campos) ou construir uma dimensão com uma coluna de chave gerada, mas o ideal é ter um código do sistema/ERP.
Checklist de chaves:
- DimProduto tem ProdutoID único.
- DimCliente tem ClienteID único.
- DimVendedor tem VendedorID único.
- DimLoja tem LojaID único.
- Fatos carregam esses IDs nas linhas.
Passo 4 — Crie/valide a DimCalendario (uma única tabela de datas)
Em modelos de negócio, use uma dimensão de calendário única para padronizar análises por tempo. Ela deve cobrir todo o período dos fatos (do menor ao maior). Evite usar várias colunas de data espalhadas como “tabela de data” separada para cada fato.
Exemplos de colunas úteis na DimCalendario:
- Data (tipo date)
- Ano, Mês (número), Nome do mês
- AnoMês (ex.: 2025-01)
- Trimestre
- Dia da semana, É fim de semana
Se você tem mais de um tipo de data no mesmo fato (ex.: data do pedido e data de faturamento), você pode manter as duas colunas na fato e usar relacionamentos diferentes (um ativo e outro inativo) com a mesma DimCalendario, escolhendo o relacionamento via medida quando necessário.
Passo 5 — Monte os relacionamentos no Modelo (visão de diagrama)
No Power BI, após carregar as tabelas, vá para a visão de Modelo e crie os relacionamentos:
- DimProduto[ProdutoID] 1:* FatoVendas[ProdutoID]
- DimCliente[ClienteID] 1:* FatoVendas[ClienteID] (se existir)
- DimVendedor[VendedorID] 1:* FatoVendas[VendedorID] (se existir)
- DimLoja[LojaID] 1:* FatoVendas[LojaID] (se existir)
- DimCalendario[Data] 1:* FatoVendas[Data]
Direção de filtro: em geral, mantenha Single (dimensão filtra fato). Evite “Both” (bidirecional) como padrão, porque pode criar ambiguidade e resultados inesperados quando há múltiplos caminhos de filtro.
Exemplo prático: modelagem de vendas por item (com dimensões)
Imagine que sua FatoVendas tenha estas colunas mínimas:
- VendaID
- ItemSequencia
- DataVenda
- ProdutoID
- ClienteID (opcional)
- VendedorID (opcional)
- LojaID (opcional)
- Quantidade
- ValorBruto
- Desconto
- ValorLiquido
E dimensões:
- DimProduto: ProdutoID, Produto, Categoria, Marca
- DimCliente: ClienteID, Cliente, Cidade, UF
- DimVendedor: VendedorID, Vendedor, Equipe
- DimLoja: LojaID, Loja, Região
- DimCalendario: Data, Ano, Mês, AnoMês
Com isso, um gráfico de vendas por categoria funciona porque o filtro “Categoria” (DimProduto) chega na FatoVendas via ProdutoID. E um filtro de período (DimCalendario) chega na FatoVendas via DataVenda.
Medidas básicas (exemplos) que se beneficiam do modelo estrela
Vendas Líquidas = SUM(FatoVendas[ValorLiquido])Quantidade Vendida = SUM(FatoVendas[Quantidade])Ticket Médio = DIVIDE([Vendas Líquidas], DISTINCTCOUNT(FatoVendas[VendaID]))Essas medidas ficam simples porque o modelo garante que filtros de produto, cliente, vendedor e data se apliquem corretamente.
Quando você tem mais de uma tabela fato: vendas, recebimentos e estoque
É comum ter múltiplos processos com granularidades diferentes. O segredo é não forçar tudo em uma única fato e, ao mesmo tempo, compartilhar dimensões quando fizer sentido.
Fatos diferentes, dimensões compartilhadas
Exemplo de compartilhamento:
- DimProduto se relaciona com FatoVendas e FatoMovEstoque.
- DimCalendario se relaciona com FatoVendas (DataVenda), FatoRecebimentos (DataRecebimento) e FatoMovEstoque (DataMovimento).
- DimLoja pode se relacionar com todas, se a loja existir em todos os processos.
Isso permite comparar, por exemplo, vendas e saídas de estoque por produto e por mês, sem misturar granularidades na mesma tabela.
Cuidado com “cabeçalho e itens” (duas tabelas de vendas)
Algumas fontes trazem:
- VendasCabecalho (uma linha por venda)
- VendasItens (várias linhas por venda)
Para análise de produto, normalmente você usa VendasItens como fato principal. O cabeçalho pode virar:
- Uma dimensão (se tiver atributos que não existem nos itens e forem 1:1 com a venda), ou
- Uma tabela auxiliar relacionada por VendaID, com cuidado para não criar ambiguidade.
Regra prática: se você já tem os valores financeiros nos itens (ValorLiquido por item), evite também somar valores do cabeçalho no mesmo relatório, pois isso pode duplicar totais quando o cabeçalho se relaciona com itens.
Granularidade e armadilhas comuns (e como evitar)
Armadilha 1 — Misturar granularidades na mesma tabela
Exemplo: colocar na FatoVendas uma coluna “ValorRecebido” que vem de recebimentos por parcela. Se uma venda tem 3 parcelas, você pode acabar repetindo o valor recebido em 3 linhas de itens, inflando totais.

Como evitar: mantenha recebimentos em uma fato própria (FatoRecebimentos) e relacione por VendaID apenas se isso não criar duplicidade. Muitas vezes, a ligação mais segura é via dimensões comuns (Data, Cliente, Loja) e não diretamente por VendaID, dependendo do seu caso.
Armadilha 2 — Relacionamento muitos-para-muitos sem necessidade
Muitos-para-muitos pode ser útil em casos específicos, mas em modelos de pequenos negócios costuma ser sinal de chave mal definida ou dimensão duplicada.
Como evitar:
- Garanta unicidade nas dimensões (ProdutoID único).
- Remova duplicatas na dimensão.
- Evite relacionar por colunas textuais (nome do produto) que podem variar.
Armadilha 3 — Dimensão com valores “quebrados” (cadastro inconsistente)
Se o mesmo ProdutoID aparece com duas categorias diferentes na DimProduto, o filtro por categoria pode ficar incoerente.
Como evitar:
- Trate a dimensão como “fonte de verdade” do cadastro.
- Se a categoria muda ao longo do tempo e você precisa histórico, isso vira um tema de dimensão com histórico (SCD). Se não precisa, mantenha apenas o cadastro atual.
Armadilha 4 — Usar “Both” em vários relacionamentos
Bidirecional pode parecer resolver filtros, mas pode criar loops e resultados inesperados quando você adiciona novas tabelas.
Como evitar:
- Use direção única como padrão.
- Se precisar filtrar uma dimensão a partir de outra (ex.: filtrar produtos que venderam no período), prefira medidas e visuais adequados, ou tabelas ponte bem definidas.
Passo a passo prático: checklist de confiabilidade do modelo
1) Valide unicidade das dimensões
No Power BI (ou no Power Query), confira se cada dimensão tem uma chave sem duplicatas. Uma forma prática é criar uma tabela de verificação (ou usar “Remover Duplicatas” na chave e comparar contagens).
O que procurar:
- ProdutoID duplicado na DimProduto
- ClienteID duplicado na DimCliente
- LojaID duplicado na DimLoja
2) Verifique se os fatos têm correspondência nas dimensões
Se a FatoVendas tem ProdutoID que não existe na DimProduto, você terá linhas “órfãs” que não respondem a filtros de produto/categoria.
Como checar na prática:
- Crie um visual de tabela com FatoVendas[ProdutoID] e conte linhas; depois tente cruzar com DimProduto[ProdutoID].
- Procure pelo item “(Blank)” em filtros de Produto/Categoria; isso costuma indicar chaves sem correspondência.
3) Padronize tipos de dados das chaves
ProdutoID como texto em uma tabela e número em outra impede relacionamento correto ou cria conversões implícitas.
Checklist:
- ProdutoID é o mesmo tipo em todas as tabelas (texto ou inteiro, mas consistente).
- Datas são do tipo date (não texto).
4) Confirme a granularidade com testes de soma
Faça testes simples para detectar duplicidade:
- Some ValorLiquido por mês e compare com o total esperado da fonte.
- Conte DISTINCTCOUNT de VendaID e compare com o número de vendas.
Se os totais mudam quando você adiciona uma dimensão que “não deveria” afetar (por exemplo, uma dimensão de produto alterando o total geral sem filtro), pode haver relacionamento incorreto ou duplicidade na dimensão.
Modelagem para estoque: movimentos vs. saldo
Para estoque, há dois jeitos comuns de modelar:
- FatoMovEstoque (movimentos): entradas e saídas. Permite reconstruir saldo ao longo do tempo e auditar eventos.
- FatoSaldoEstoque (snapshot): uma linha por Produto + Data (ou Produto + Mês) com saldo naquele momento. Mais rápido para análises de saldo, mas depende de como o snapshot é gerado.
Em pequenos negócios, movimentos costumam ser mais confiáveis quando você precisa entender “por que” o estoque mudou. Snapshot é útil quando você recebe do sistema um saldo diário/mensal pronto e não tem o detalhe dos movimentos.
Granularidade típica:
- Movimentos: cada linha = ProdutoID + DataHora + TipoMovimento + QuantidadeMov
- Snapshot: cada linha = ProdutoID + Data + Saldo
Dimensões compartilhadas: DimProduto, DimLoja (se houver), DimCalendario.
Boas práticas de nomenclatura e organização (para manter simples)
Prefixos e nomes claros
Adote um padrão:
- FatoVendas, FatoRecebimentos, FatoMovEstoque
- DimProduto, DimCliente, DimLoja, DimCalendario
Colunas de chave com sufixo ID:
- ProdutoID, ClienteID, LojaID, VendedorID
Evite colunas descritivas dentro do fato
Se você já tem DimProduto com Categoria e Marca, não replique Categoria e Marca na FatoVendas. Isso reduz tamanho e evita divergência.
Crie uma “DimStatus” apenas se fizer sentido
Alguns campos (Status do pedido, Forma de pagamento, Tipo de movimento) podem ser dimensões pequenas. Se esses valores são poucos e estáveis, você pode mantê-los como colunas no fato. Se precisam de descrições, agrupamentos e padronização, uma dimensão dedicada ajuda.
Exemplo guiado: do “tabelão” para um modelo estrela
Suponha que você recebeu uma planilha única com colunas: Data, Produto, Categoria, Cliente, Cidade, Vendedor, Loja, Quantidade, ValorLiquido. Isso funciona como um tabelão, mas você quer um modelo mais confiável.
Passo a passo de transformação lógica (nível de modelagem)
- 1) Identifique a fato: as colunas Quantidade e ValorLiquido indicam evento de venda. Defina: cada linha representa um item vendido (se não houver ItemID, a granularidade pode ser “registro de venda” da planilha).
- 2) Separe dimensões: Produto/Categoria viram DimProduto; Cliente/Cidade viram DimCliente; Vendedor vira DimVendedor; Loja vira DimLoja; Data vira DimCalendario.
- 3) Crie chaves: idealmente, ProdutoID, ClienteID etc. Se não existirem, você pode criar chaves substitutas (por exemplo, um índice) na dimensão e fazer o merge para trazer o ID para a fato.
- 4) Remova da fato as colunas descritivas (Produto, Categoria, Cliente, Cidade…) e mantenha apenas os IDs e métricas.
- 5) Crie relacionamentos 1:* das dimensões para a fato.
Resultado: você passa a ter um modelo onde mudanças de cadastro (ex.: corrigir categoria) acontecem na dimensão, e o relatório inteiro se ajusta sem precisar reprocessar “texto repetido” em milhões de linhas.
Quando usar tabela ponte (bridge) e como não complicar
Tabela ponte é útil quando existe relação muitos-para-muitos real, por exemplo:
- Produto pode ter múltiplos fornecedores e fornecedor atende múltiplos produtos.
- Cliente pode pertencer a múltiplos grupos (ex.: segmentos de marketing).
Nesse caso, você cria:
- DimFornecedor
- BridgeProdutoFornecedor (ProdutoID, FornecedorID)
Mesmo assim, mantenha o resto do modelo em estrela. Use ponte apenas onde a relação realmente exige.
Resumo operacional: regras simples para um modelo que “não quebra”
- Defina a granularidade de cada fato com a frase “cada linha representa…”.
- Use dimensões para atributos descritivos; fatos para métricas e chaves.
- Relacione por IDs consistentes (mesmo tipo de dado).
- Prefira relacionamentos 1:* e filtro em direção única.
- Compartilhe DimCalendario e DimProduto entre fatos quando fizer sentido.
- Teste totais e procure “(Blank)” para identificar chaves órfãs.


